
گوگل که منابع بسیار زیادی در اختیار دارد، اولین شرکتی نبود که از OpenAI تقلید کرد. کمتر از 3 ماه پس از راهاندازی o1، علیبابا، غول تجارت الکترونیک چینی، نسخه جدیدی از چتبات خود به نام «کوئن» (Qwen) با قابلیتهای «استدلالی» مشابه منتشر کرد. این شرکت در پست وبلاگی پرزرقوبرقی با لینکی به نسخه رایگان مدل، پرسید: «تفکر، پرسش و درک به چه معناست؟» شرکت چینی دیگری به نام دیپ سیک (DeepSeek) نیز یک هفته قبل از آن، مدل استدلالی خود به نام R1 را منتشر کرده بود؛ بنابراین میتوان گفت این 2 شرکت چینی باوجود تلاشهای دولت آمریکا برای محدود و عقب نگهداشتن صنعت هوش مصنوعی چین، فاصله فناوری خود با همتایان آمریکاییشان را بهشدت کاهش دادهاند و فقط چند هفته پس از اینکه شرکتهای آمریکایی رقیب فناوری جدید خود را عرضه کردند، آنها هم فناوری مشابهی به میدان آمدند.
شرکتهای چینی فقط در حوزه مدلهای استدلالی پیشتاز نیستند، بلکه دیپ سیک دسامبر مدل زبانی بزرگ جدیدی به نام v3 منتشر کرد. v3 تقریباً ۷۰۰ گیگابایت حجم دارد؛ به همین دلیل حجم آن برای اجرا روی هر سختافزاری بهجز سختافزارهای تخصصی زیاد است. در ضمن، ۶۸۵ میلیارد پارامتر دارد. مدل v3 از تمام مدلهای رایگانی که تا به امروز منتشر شدهاند بزرگتر و قدرتمندتر است. Llama 3.1، مدل زبانی بزرگ پرچمدار متا که ژوئیه منتشر شد، فقط ۴۰۵ میلیارد پارامتر دارد (نمودار زیر را ببینید).
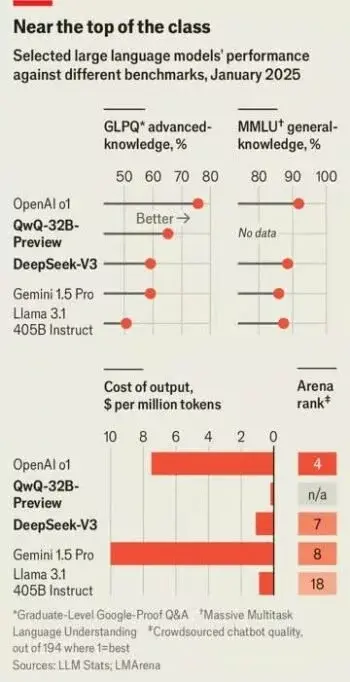
مدل زبانی بزرگی که دیپ سیک از آن استفاده میکند نهفقط از بسیاری همتایان غربی خود بزرگتر است، بلکه برتریهایی هم نسبت به آنها دارد و با مدلهای انحصاری گوگل و OpenAI برابری میکند. «پل گوتیه» (Paul Gauthier)، بنیانگذار ایدر «ایدر» (Aider)، پلتفرم کدنویسی هوش مصنوعی، v3، را روی بنچمارک کدنویسی خود اجرا کرد و متوجه شد این مدل از همه رقبایش، بهجز o1، پیشی گرفته است. این مدل در رتبهبندی چتباتها به نام Lmsys در رتبه هفتم قرار گرفته است. جایگاه مدل جدید شرکت دیپ سیک در این رتبهبندی از تمام مدلهای متنباز موجود بالاتر است و برترین مدلی محسوب میشود که شرکتی غیر از گوگل یا OpenAI تولید کرده.
اکنون صنعت هوش مصنوعی چین ازنظر کیفیت بهقدری به رقبای آمریکایی خود نزدیک شده که سم آلتمن، مدیرعامل OpenAI، خود را ملزم به توضیح درباره کاهش این فاصله میداند. او مدت کوتاهی پس از انتشار v3 دیپ سیک با ناراحتی توییتی با متن زیر منتشر کرد:
کپیکردن چیزی که میدانید کار میکند (نسبتاً) آسان است اما انجام کاری جدید، پرخطر و دشوار که نمیدانید جواب میدهد یا نه، بسیار سخت است.
دلایل پیشرفت صنعت هوش مصنوعی چین

صنعت هوش مصنوعی چین ابتدا دستدوم به نظر میرسید؛ شاید دلیل آن تا حدی به لزوم مقابله چین با تحریمهای آمریکا مربوط شود. سال ۲۰۲۲، آمریکا صادرات تراشههای پیشرفته به چین را ممنوع کرد و باعث شد انویدیا، شرکت پیشتاز آمریکایی در زمینه ساخت پردازندههای گرافیکی، نسخههای ویژهای از محصولاتش را برای بازار چین طراحی کند که عملکرد پایینتری داشتند. در ضمن، آمریکا با حربههایی تلاش کرد مانع توسعه توانایی چین برای تولید تراشههای پیشرفته در داخل کشور شود؛ مانند ممنوعیت صادرات تجهیزات لازم و تهدید به مجازات شرکتهای غیرآمریکایی که ممکن است به چین کمک کنند.
مانع دیگر پیشرفت صنعت هوش مصنوعی در چین عامل داخلی است؛ شرکتهای چینی دیر به مدلهای زبانی بزرگ روی آوردند و یکی از دلایل این تأخیر نگرانیهای نظارتی بود. نگران واکنش سانسورچیها به مدلهایی بودند که ممکن است «توهم» ایجاد کنند و اطلاعات نادرست ارائه دهند یا بدتر از آن، جملات سیاسی خطرناکی بیان کنند. بایدو، موتور جستجوی چینی، سالها با مدل زبانی بزرگ بومی آزمایش شده بود و مدلی به نام «ERNIE» ایجاد کرده بود اما در انتشار آن برای عموم مردم تردید داشت. حتی وقتی موفقیت ChatGPT باعث شد این شرکت در رویکردش تجدیدنظر کند، ابتدا دسترسی به ERNIEbot را فقط از طریق دعوت امکانپذیر کرد.
مقامات چینی درنهایت مقرراتی برای ارتقای صنعت هوش مصنوعی وضع کردند. اگرچه از سازندگان مدل خواستند بر محتوای سالم تمرکز کنند و به «ارزشهای سوسیالیستی» پایبند باشند، متعهد شدند «توسعه نوآورانه هوش مصنوعی تولیدی» را نیز تشویق کنند.
مدل کوئن علی بابا یک سال تمام هیچ هیجانی نداشت و فقط مدل زبانی مبتنیبر مدل زبان بزرگ متنباز Llama متا محسوب میشد اما در سال ۲۰۲۴ که علیبابا نسخههای متوالی آن را منتشر کرد، کیفیتش بهتر و بهتر شد.
جک کلارک (Jack Clark)، محقق فعال در آزمایشگاه هوش مصنوعی غربی آنتروپیک، یک سال پیش وقتی علی بابا کوئن را منتشر کرد و فقط توانایی تحلیل تصاویر و متن را داشت، درباره مدلهای زبان بزرگ چینی گفت:
به نظر میرسد این مدلها با مدلهای بسیار قدرتمندی که در آزمایشگاههای پیشرو غرب توسعه یافتهاند، رقابت میکنند.
دیگر غولهای اینترنتی چین، ازجمله هواوی و تنسنت، نیز مشغول ساخت مدلهای خودشاناند اما درمورد دیپ سیک قضیه کاملاً فرق میکند؛ این شرکت حتی زمانی که علیبابا اولین مدل کوئن را منتشر کرد، نیز هنوز وجود نداشت. دیپ سیک زیرمجموعه های فلایر (High-Flyer) محسوب میشود. های فلایر صندوق سرمایهگذاری مشترکی است که سال ۲۰۱۵ برای استفاده از هوش مصنوعی در دستیابی به برتری در تجارت سهام تأسیس شد.
البته انگیزههای شرکتهای هوش مصنوعی چینی صرفاً تجاری نبودند. به گفته «لیانگ ونفنگ» (Liang Wenfeng)، بنیانگذار های فلایر، اولین حامیان OpenAI بهدنبال بازگشت سرمایه نبودند و به گفته او انگیزه حامیان این شرکت «دنبالکردن مأموریت» بود. های فلایر سال ۲۰۲۳ که کوئن راهاندازی شد، اعلام کرد میخواهد وارد مسابقه ایجاد هوش مصنوعی در سطح انسان شود و واحد تحقیقاتی هوش مصنوعی خود را با عنوان دیپ سیک به راه انداخت.
دیپ سیک نیز مانند OpenAI وعده داد هوش مصنوعی را برای منفعت عمومی توسعه دهد. آقای لیانگ اذعان کرد این شرکت نتایج آموزش خود را عمومی خواهد کرد تا از «انحصاری شدن» فناوری در دست چند فرد یا شرکت جلوگیری کند. دیپ سیک برخلاف OpenAI که مجبور شد برای پوشش هزینههای افزایشی آموزش دنبال تأمین مالی خصوصی بگردد، همیشه به منابع عظیم قدرت محاسباتیهای فلایر دسترسی داشته است.
تنها ویژگی قابلتوجه مدل زبانی بزرگ دیپ سیک مقیاسش نیست، بلکه به این دلیل که هنگام آموزش از انرژی کمی مصرف شده است، توانست نظرات را جلب کند. در این فرایند، مدل با دادههایی تغذیه میشود که با استفاده از آنها پارامترهای خود را استنتاج میکند. به گفته نیک لین (Nic Lane) از دانشگاه کمبریج، دلیل چنین موفقیتی بهرهمندی از یک نوآوری بزرگ نبود و فقط مجموعهای از بهبودهای جزئی عامل دستیابی به آن بودند.
برای مثال، در فرایند آموزش، معمولاً از گردکردن برای سادهسازی محاسبات استفاده میشود اما درصورت لزوم، اعداد با دقت حفظ میشدند. مزرعه سرور بهگونهای بازپیکربندی شد که تراشهها بتوانند کارآمدتر با یکدیگر ارتباط برقرار کنند. مدل پس از آموزش، با استفاده از خروجی از سیستم استدلال DeepSeek R1، دقیق تنظیم شد تا یاد بگیرد چگونه کیفیت این سیستم را با هزینه کمتر تقلید کند.
به لطف این نوآوریها و نوآوریهای دیگر، ایجاد میلیاردها پارامتر v3 کمتر از 3 میلیون ساعت خالص طول کشید و با هزینه تقریبی کمتر از 6 میلیون دلار ایجاد شد. قدرت محاسباتی و هزینه صرفشده ایجاد v3 یکدهم قدرت محاسباتی و هزینهای است که برای Llama 3.1 صرف شد. آموزش v3 فقط به 2000 تراشه نیاز داشت اما برای آموزش Llama 3.1 از 16000 تراشه استفاده شد. این نکته را هم باید یادآوری کنیم که بهدلیل تحریمهای آمریکا، تراشههای استفادهشده در v3 حتی قدرتمندترین تراشهها هم نبودند. به نظر میرسد شرکتهای غربی در استفاده از تراشهها بسیار بیپرده و بدون محدودیت عمل میکنند؛ برای مثال متا قصد دارد مزرعه سروری با 350 هزار تراشه بسازد.
v3 نهفقط با هزینه کمتری نسبت به سایر مدلها آموزش داده شده، بلکه اجرای آن نیز با هزینه کمتری امکانپذیر است. دیپ سیک وظایف را بهتر از همتایان خود بین چندین تراشه تقسیم میکند و قبل از اتمام مرحله قبلی فرایند، مرحله بعدی را آغاز میکند. این کار به آن اجازه میدهد از ظرفیت کامل تمام تراشهها استفاده کند و کمترین تراکم کاری را داشته باشند. دیپ سیک قصد دارد در آینده نزدیک به سایر شرکتها اجازه دهد خدماتی را بر پایه بهرهمندی از تواناییهای v3 ایجاد کنند؛ درصورت فراهمشدن چنین خدماتی، هزینه استفاده از این مدل کمتر از یکدهم هزینه استفاده از کلاد، مدل زبانی بزرگ آنتروپیک، خواهد بود. سیمون ویلیسون (Simon Willison)، کارشناس هوش مصنوعی، درباره این موضوع گفته است:
اگر عملکرد مدلهای زبانی بزرگ چینی با نمونههای مشابه غربی آنها برابری کند، شاهد رقابتی بزرگ در عرصه هزینه استفاده از چنین مدلهایی خواهیم بود.
تلاش دیپ سیک برای کارآمد شدن به همین جا ختم نشده است؛ این شرکت علاوهبر انتشار نسخه کامل مدل R1 مجموعهای از نسخههای کوچکتر، ارزانتر و سریعتر «پالایششده» آن را نیز عرضه کرد که تقریباً به اندازه مدل اصلی، قدرتمندند. این اقدام دیپ سیک مشابه انتشار نسخههای مختلف مدلهای مشابه علی بابا و متا بود و این شرکت بار دیگر ثابت کرد میتواند با بزرگترین نامهای تجاری رقابت کند.
علیبابا و دیپ سیک به روش دیگری نیز با آزمایشگاههای پیشرفته غربی رقابت میکنند؛ این دو شرکت برخلاف OpenAI و گوگل، مانند متا سیستمهای خود را با مجوز منبعباز در دسترس قرار میدهند. اگر بخواهید هوش مصنوعی کوئن را دانلود و پلتفرم برنامهنویسی خود را بر پایه آن بسازید، میتوانید این کار را راحت انجام دهید و هیچ مجوز خاصی لازم ندارید. این آزادی عمل شفافیت فوقالعادهای دارد؛ هر دو شرکت هر مرتبه پس از انتشار مدلهای جدید، مقالاتی منتشر میکنند که جزئیات زیادی درباره تکنیکهای استفادهشده برای بهبود عملکردشان بیان میکند.
دلایل قابل رقابت بودن مدلهای AI چینی با نمونههای مشابه آمریکایی
وقتی علیبابا مدل QwQ را که مخفف «Questions with Qwen» است منتشر کرد، به اولین شرکت جهان تبدیل شد که چنین مدلی را با مجوز باز منتشر کرد. علی بابا به هر کاربری اجازه میدهد فایل کامل 20 گیگابایتی را دانلود و روی سیستمش اجرا کند یا آن را جدا کند و ببیند چگونه کار میکند. این رویکرد بهطور قابلتوجهی با رویکرد OpenAI متفاوت است. OpenAI کارکردهای داخلی مدل o1 خود را مخفی نگه میدارد.
بهطورکلی، هر 2 مدل از چیزی به نام «محاسبات در زمان آزمون» استفاده میکنند. آنها بهجای تمرکز بر استفاده از قدرت محاسباتی حین آموزش مدل، هنگام پاسخ به سؤالات نیز بیشتر از نسلهای قبلی مدلهای زبانی بزرگ مصرف میکنند. این رویکرد در زمینههایی مانند ریاضیات و برنامهنویسی نتایج امیدوارکنندهای داشته است.
اگر از شما سؤالی ساده مثلاً (نام پایتخت فرانسه) بشود، احتمالاً با اولین کلمهای که به ذهنتان میآید، پاسخ میدهید و به احتمال زیاد درست خواهد بود. چتبات معمولی نیز به همین روش کار میکند
اگر از شما سؤال پیچیدهتری بشود، میخواهید آن را به روشی ساختاریافتهتر بررسی کنید. اگر ازتان خواسته شود پنجمین شهر پرجمعیت فرانسه را نام ببرید، احتمالاً ابتدا لیستی طولانی از شهرهای بزرگ فرانسه تهیه میکنید؛ سپس میکوشید آنها را براساس جمعیت مرتب کنید و بعد پاسخ دهید.
o1 و مدلهای مشابه آن میتوانند مدل زبان بزرگ را بهسمت همان نوع تفکر ساختاری سوق دهند. سیستمی که آنها را در بر دارد، بهجای اینکه به پاسخ قابلقبولترین موردی که به ذهن میآید، بپردازد، ابتدا مسئله را تجزیه میکند و گامبهگام به پاسخ میرسد.
o1 افکارش را نزد خودش نگه میدارد و فقط خلاصهای از فرایند خودش و نتیجه نهایی کارش را در اختیار کاربران قرار میدهد. OpenAI برخی توجیهاتش برای دنبالکردن چنین مدلی را گفته است؛ برای مثال، گاهی مدل ممکن است درباره استفاده از کلمات توهینآمیز یا افشای اطلاعات خطرناک فکر کند اما بعد تصمیم میگیرد این کار را نکند. اگر استدلال کامل آن آشکار شود، موارد حساس نیز فاش خواهند شد.
علیبابا چنین نگرانیهایی ندارد. اگر از QwQ بخواهید مسئلهی ریاضی دشواری را حل کند، بیپروا هر مرحله از مسیر را با جزئیات توضیح میدهد، گاهی هزاران کلمه با خودش صحبت و روشهای مختلفی را برای حل مسئله امتحان میکند.
ایسو کانت (Eiso Kant) همبنیانگذار پول ساید (Poolside) است؛ شرکت تولیدکننده ابزار هوش مصنوعی برای برنامهنویسان که در پرتغال مستقر است. او باور دارد متنباز بودن مدل شرکت علی بابا تصادفی نیست؛ آزمایشگاههای چینی هوش مصنوعی مانند سایر صنعتها، برای جذب استعدادها تلاش میکنند.
البته مدلهای چینی معایبی هم دارند؛ برای مثال، اگر از DeepSeek v3 درباره تایوان سؤال کنید، پاسخ میدهد تایلند جزیرهای در شرق آسیاست که رسماً بخشی از جمهوری چین شناخته میشود اما پس از نوشتن چند جمله در این زمینه، پاسخ خود را متوقف و پاسخ اولیه را حذف میکند و بهجای آن فقط میگوید: «بیایید درباره چیز دیگری صحبت کنیم»!
آزمایشگاههای چینی AI شفافتر از دولت این کشورند؛ زیرا میخواهند اکوسیستمی از شرکتها را حول محور هوش مصنوعی خود ایجاد کنند. چنین هدفی ارزش تجاری دارند. شرکتهایی که براساس مدلهای متنباز ساخته میشوند، ممکن است درنهایت متقاعد شوند محصولات یا خدماتی از سازندگان آن بخرند. در ضمن، چنین رویکردی در جریان درگیری چین با آمریکا بر سر هوش مصنوعی، مزیت استراتژیکی برای این کشور به ارمغان میآورد.
درکل، شرکتهای چینی ترجیح میدهند از مدلهای AI چینی استفاده کنند؛ زیرا دیگر نگران محدودیتها و ممنوعیتهایی که شرکتهای غربی اعلام کردهاند یا تحریمهای آنها نخواهند بود؛ همچنین درباره سانسورهایی که باید در چین انجام شود و مدلهای غربی به آنها توجه نمیکنند، نیز نگران نخواهند بود.
«فرانسیس یانگ» (Francis Young)، سرمایهگذار فناوری مستقر در شانگهای، یادآوری کرده همکاری شرکای محلی با شرکتهایی مانند اپل و سامسونگ که مشتاق استفاده از هوش مصنوعی در دستگاههای درحال فروش در چین هستند، ضروری است. حتی برخی شرکتهای خارجی دلایل خاصی برای استفاده از مدلهای چینی دارند؛ کوئن عمداً بر زبانهایی مانند اردو و بنگالی که منابع کمی با آنها ایجاد شدهاند، تسلط دارد؛ بنابراین میتوان گفت با منابع کاملی آموزش دیده است. در مقابل مدلهای آمریکایی بیشتر با دادههای انگلیسی آموزش داده میشوند. در ضمن همانطور که گفتیم، هزینه کم اجرای مدلهای چین آنها را جذاب کرده است.
صنعت هوش مصنوعی چین تهدیدی جدی برای آمریکا؟
در پایان باید بگوییم دفاع ما از مدلهای AI و چتباتهای چینی لزوماً به معنای پیشرفت حتی آنها در آینده نیست؛ زیرا پلتفرمهای هوش مصنوعی آمریکایی همچنان قابلیتهایی دارند که در رقبای چینیشان دیده نمیشود؛ برای مثال چتباتهای کلاد و OpenAI نهفقط در نوشتن کدها، بلکه در اجرای آنها نیز کمکتان میکنند. کلاد تمام اپلیکیشنها را ایجاد و میزبانی خواهد کرد. استدلال گامبهگام تنها راهحل مسائل پیچیده نیست. میتوانید از نسخه معمولی ChatGPT همان سؤال ریاضی را بکنید که از نسخه پیشرفتهتر آن میپرسید و چت پات در پاسخ برنامهای ساده برای پاسخ به سؤال شما مینویسد.
انتظار میرود Open AI بهزودی خبر ایجاد «ابرعامل در سطح دکترا» را اعلام کند. این ابرعامل با توانایی برابر با انسان در زمینه انجام وظایف مختلف علمی را نوآوریهای بیشتری در راه است. به گفته آقای آلتمن ممکن است رقابت حاضر با صنعت هوش مصنوعی آمریکا، به تحقق اهداف بزرگتر این صنعت منجر شود.






